Note
Go to the end to download the full example code.
Multi-domain Linear Monge Alignment
This example illustrates the use of the MultiLinearMongeAlignmentAdapter
# Author: Remi Flamary
#
# License: BSD 3-Clause
# sphinx_gallery_thumbnail_number = 4
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LogisticRegression
from skada import (
MultiLinearMongeAlignmentAdapter,
make_da_pipeline,
source_target_split,
)
from skada.datasets import make_shifted_datasets
Generate conditional shift classification dataset and plot it
We generate a simple 2D conditional shift dataset.
X, y, sample_domain = make_shifted_datasets(
n_samples_source=20,
n_samples_target=20,
shift="conditional_shift",
noise=0.2,
label="multiclass",
random_state=42,
)
Xs, Xt, ys, yt = source_target_split(X, y, sample_domain=sample_domain)
plt.figure(5, (10, 5))
plt.subplot(1, 2, 1)
plt.scatter(Xs[:, 0], Xs[:, 1], c=ys, cmap="tab10", vmax=9, label="Source")
plt.title("Source data")
ax = plt.axis()
plt.subplot(1, 2, 2)
plt.scatter(Xt[:, 0], Xt[:, 1], c=yt, cmap="tab10", vmax=9, label="Target")
plt.title("Target data")
plt.axis(ax)
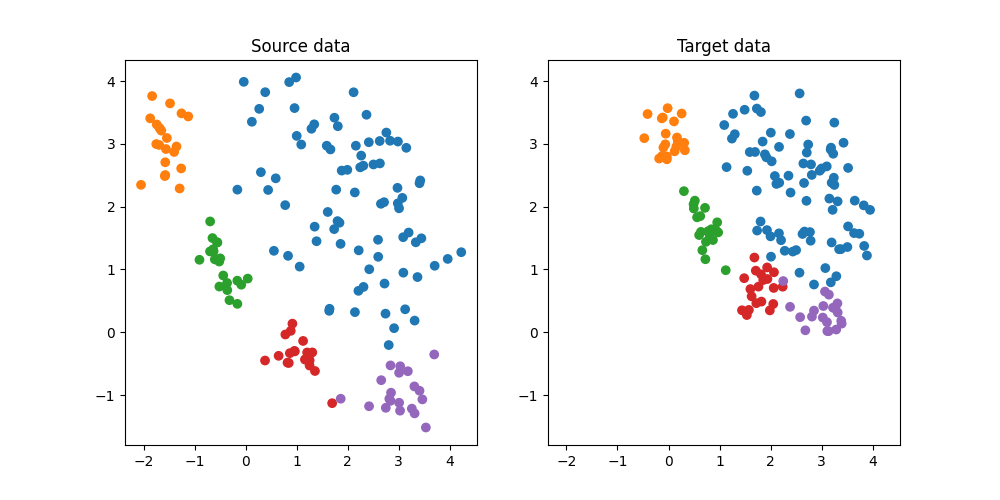
(np.float64(-2.3676169789533272), np.float64(4.53817259426296), np.float64(-1.7964573229829714), np.float64(4.336863129384494))
Train a classifier on source data
We train a simple SVC classifier on the source domain and evaluate its performance on the source and target domain. Performance is much lower on the target domain due to the shift. We also plot the decision boundary
clf = MultiLinearMongeAlignmentAdapter()
clf.fit(X, sample_domain=sample_domain)
X_adapt = clf.transform(X, sample_domain=sample_domain, allow_source=True)
plt.figure(5, (10, 3))
plt.subplot(1, 3, 1)
plt.scatter(Xs[:, 0], Xs[:, 1], c=ys, cmap="tab10", vmax=9, label="Source")
plt.title("Source data")
ax = plt.axis()
plt.subplot(1, 3, 2)
plt.scatter(Xt[:, 0], Xt[:, 1], c=yt, cmap="tab10", vmax=9, label="Target")
plt.title("Target data")
plt.axis(ax)
plt.subplot(1, 3, 3)
plt.scatter(
X_adapt[sample_domain >= 0, 0],
X_adapt[sample_domain >= 0, 1],
c=y[sample_domain >= 0],
marker="o",
cmap="tab10",
vmax=9,
label="Source",
alpha=0.5,
)
plt.scatter(
X_adapt[sample_domain < 0, 0],
X_adapt[sample_domain < 0, 1],
c=y[sample_domain < 0],
marker="x",
cmap="tab10",
vmax=9,
label="Target",
alpha=1,
)
plt.legend()
plt.title("Adapted data")
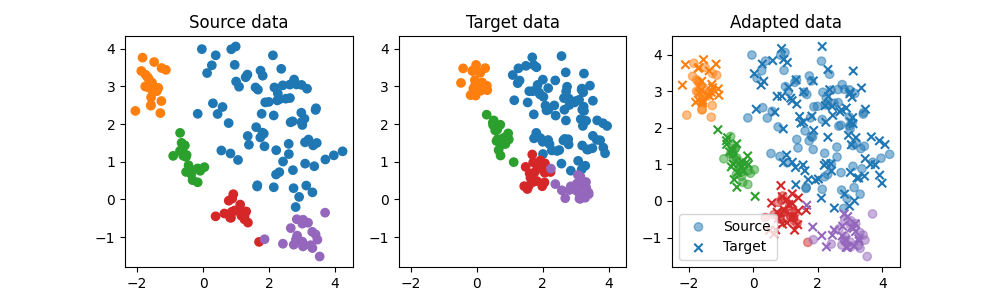
Text(0.5, 1.0, 'Adapted data')
Train a classifier on adapted data
clf = make_da_pipeline(
MultiLinearMongeAlignmentAdapter(),
LogisticRegression(),
)
clf.fit(X, y, sample_domain=sample_domain)
print(
"Average accuracy on all domains:",
clf.score(X, y, sample_domain=sample_domain, allow_source=True),
)
Average accuracy on all domains: 0.9875
def get_multidomain_data(
n_samples_source=100,
n_samples_target=100,
noise=0.1,
random_state=None,
n_sources=3,
n_targets=2,
):
np.random.seed(random_state)
X, y, sample_domain = make_shifted_datasets(
n_samples_source=n_samples_source,
n_samples_target=n_samples_target,
noise=noise,
shift="conditional_shift",
label="multiclass",
random_state=random_state,
)
for ns in range(n_sources - 1):
Xi, yi, sample_domaini = make_shifted_datasets(
n_samples_source=n_samples_source,
n_samples_target=n_samples_target,
noise=noise,
shift="conditional_shift",
label="multiclass",
random_state=random_state + ns,
mean=np.random.randn(2),
sigma=np.random.rand(2) * 0.5 + 0.5,
)
Xs, Xt, ys, yt = source_target_split(Xi, yi, sample_domain=sample_domaini)
X = np.vstack([X, Xt])
y = np.hstack([y, yt])
sample_domain = np.hstack([sample_domain, np.ones(Xt.shape[0]) * (ns + 2)])
for nt in range(n_targets - 1):
Xi, yi, sample_domaini = make_shifted_datasets(
n_samples_source=n_samples_source,
n_samples_target=n_samples_target,
noise=noise,
shift="conditional_shift",
label="multiclass",
random_state=random_state + nt + 42,
mean=np.random.randn(2),
sigma=np.random.rand(2) * 0.5 + 0.5,
)
Xs, Xt, ys, yt = source_target_split(Xi, yi, sample_domain=sample_domaini)
X = np.vstack([X, Xt])
y = np.hstack([y, yt])
sample_domain = np.hstack([sample_domain, -np.ones(Xt.shape[0]) * (nt + 1)])
return X, y, sample_domain
X, y, sample_domain = get_multidomain_data(
n_samples_source=50,
n_samples_target=50,
noise=0.1,
random_state=43,
n_sources=3,
n_targets=2,
)
Xs, Xt, ys, yt = source_target_split(X, y, sample_domain=sample_domain)
plt.figure(5, (10, 5))
plt.subplot(1, 2, 1)
plt.scatter(Xs[:, 0], Xs[:, 1], c=ys, cmap="tab10", vmax=9, label="Source")
plt.title("Source data")
ax = plt.axis()
plt.subplot(1, 2, 2)
plt.scatter(Xt[:, 0], Xt[:, 1], c=yt, cmap="tab10", vmax=9, label="Target")
plt.title("Target domains")
plt.axis(ax)
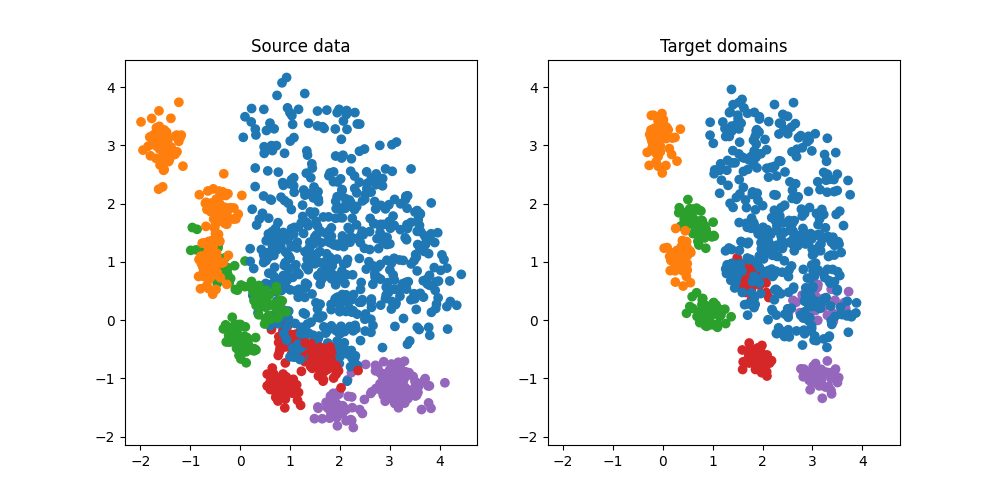
(np.float64(-2.310098338155625), np.float64(4.756925382279493), np.float64(-2.1443686989830857), np.float64(4.464886123797522))
clf = MultiLinearMongeAlignmentAdapter()
clf.fit(X, sample_domain=sample_domain)
X_adapt = clf.transform(X, sample_domain=sample_domain, allow_source=True)
plt.figure(5, (10, 3))
plt.subplot(1, 3, 1)
plt.scatter(Xs[:, 0], Xs[:, 1], c=ys, cmap="tab10", vmax=9, label="Source")
plt.title("Source data")
ax = plt.axis()
plt.subplot(1, 3, 2)
plt.scatter(Xt[:, 0], Xt[:, 1], c=yt, cmap="tab10", vmax=9, label="Target")
plt.title("Target data")
plt.axis(ax)
plt.subplot(1, 3, 3)
plt.scatter(
X_adapt[sample_domain >= 0, 0],
X_adapt[sample_domain >= 0, 1],
c=y[sample_domain >= 0],
marker="o",
cmap="tab10",
vmax=9,
label="Source",
alpha=0.5,
)
plt.scatter(
X_adapt[sample_domain < 0, 0],
X_adapt[sample_domain < 0, 1],
c=y[sample_domain < 0],
marker="x",
cmap="tab10",
vmax=9,
label="Target",
alpha=1,
)
plt.legend()
plt.axis(ax)
plt.title("Adapted data")
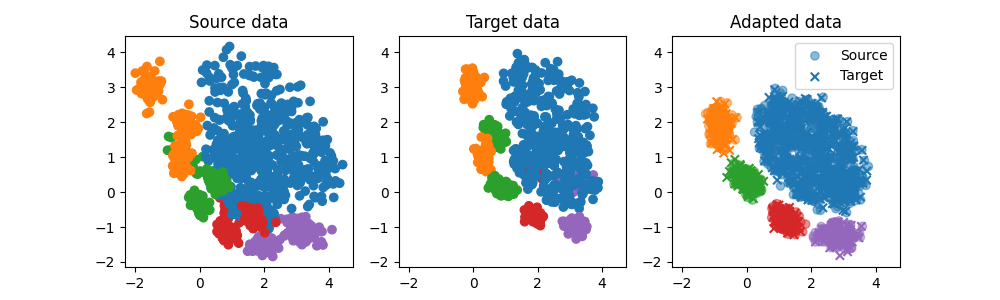
Text(0.5, 1.0, 'Adapted data')
Train a classifier on adapted data
clf = make_da_pipeline(
MultiLinearMongeAlignmentAdapter(),
LogisticRegression(),
)
clf.fit(X, y, sample_domain=sample_domain)
print(
"Average accuracy on all domains:",
clf.score(X, y, sample_domain=sample_domain, allow_source=True),
)
Average accuracy on all domains: 0.9991666666666666
Total running time of the script: (0 minutes 1.050 seconds)